Un índice climático es una medida numérica utilizada para resumir y cuantificar características específicas del clima en una región determinada. Estos índices son útiles para comprender y evaluar las condiciones climáticas y sus variaciones a lo largo del tiempo. Los índices climáticos se basan en datos observacionales, como temperaturas, precipitaciones, humedad, viento, entre otros, y se utilizan para describir fenómenos climáticos particulares.
CHIRPS es un producto de datos de precipitación a nivel global que combina observaciones de satélite y estaciones meteorológicas terrestres para generar un conjunto de datos de alta resolución espacial y temporal. Este producto es ampliamente utilizado en estudios climáticos y de hidrología.
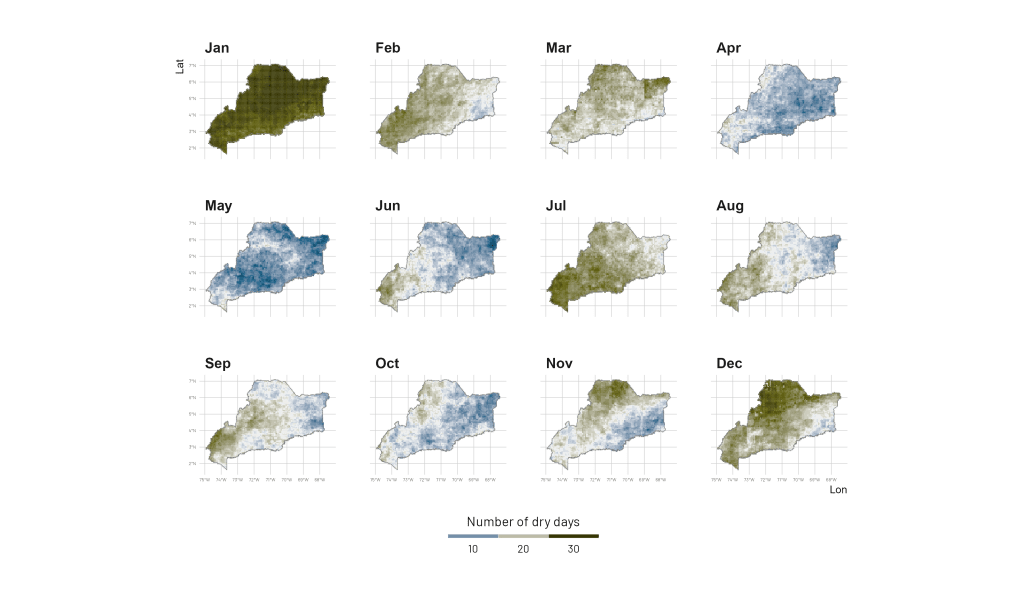
El índice de días secos basado en datos de precipitación de CHIRPS es una métrica que se utiliza para cuantificar la cantidad de días en una determinada área o región en los que no se ha registrado o ha sido muy baja la precipitación. En otras palabras, mide la cantidad de días en los que no se ha producido una cantidad significativa de lluvia.
Para calcular este índice, primero se establece un umbral de precipitación por debajo del cual un día se considera seco. Por ejemplo, si se establece un umbral de 1 mm de precipitación, cualquier día en el que la precipitación sea igual o inferior a 1 mm se consideraría un día seco. Luego, se cuentan el número de días en un período específico, como un mes o un año, que cumplen con este criterio y se calcula el porcentaje de días secos en ese período.
Este índice puede ser útil en áreas donde la disponibilidad de agua es un factor crítico para la agricultura, la gestión de recursos hídricos y otros sectores. Ayuda a cuantificar y monitorear la sequía y sus impactos en una región dada.
Aquí hemos realizado un ejemplo para el cálculo de este índice para la región de la Orinoquía de Colombia.
Código para replicar el ejercicios: https://github.com/fabiolexcastro/tutorials_youtube/tree/master/NDD