Este tutorial hace parte del siguiente vídeo de mi canal de Youtube.
Para acceder al código, da clic aquí.
Para acceder a los datos, presionar aquí.
Geografía, GIS, SIG, R, Tutorial, Análisis Espacial
Este tutorial hace parte del vídeo en mi canal de YouTube, el cuál puedes ver aquí:
Para descargarlos datos climáticos de Worldclim puedes visitar la página web (clic aquí).
El código lo puedes acceder en mi cuenta de Github (clic aquí). Y por último los datos los puedes descargar aquí (shapefiles)
Recuerda por favor este post en tu red social favorita, para que esta comunidad de R siga creciendo.
Los datos
El curso será únicamente en el lenguaje de programación de R a partir del uso de la interfaz de RStudio (IDE).
Se aconseja previamente hacer la instalación de las siguientes librerías dentro de R, así como también utilizar la última versión de R (4.1.1.)
install.packages('pacman')
library(pacman)
pacman::p_load(raster, rgdal, rgeos, stringr, sf, tidyverse, terra, ade4, ncdf4, dismo, ENMeval, rJava, readxl, caret, randomForest, hablar, imputeTS, sp, gtools, foreach, furrr, future, doSNOW, leaflet, DT, dplyr, leaflet.extras, htmltools, crosstalk, rgdal, openxlsx, png, virids, tibble, mapedit, cptcity, ggspatial, RGBIF, hrbrthemes, mapedit, plotply, broom)
Repaso en general de R. Aquí se tendrán las siguientes clases:
Variables ambientales / climáticas / topográficas
Hola a todos, quiero compartirle el curso de R

Muchas investigaciones se realizan en identificar cuál es el impacto del cambio climático sobre ciertas especies tanto animales como vegetales, dentro de los métodos para dichas investigaciones se encuentran MaxEnt y Random Forest, para hacer tales modelaciones se hace necesario contar con presencias de la especie a modelar. GBIF (Global Biodiversity Information Facility) es una plataforma que cuenta con cientos de miles de registros de presencias tanto de flora como de fauna, estos registros en su mayoría cuentan con las coordenadas geográficas que pueden ser de uso para realizar el tipo de investigaciones mencionado anteriormente.
Para hacer la descarga de tales registros se puede hacer de varias maneras, una de ellas es haciendo el respectivo registro en la página web (requiere usuario y contraseña), y luego introduciendo el nombre científico de la especie nos arroja el resultado de todos los registros, sin embargo, en muchas ocasiones el hacer la descarga se demora desde pocos minutos hasta varias horas (dependiendo del número de registros). Otro camino para descargar la información es hacer uso de la libreria RGBIF del lenguaje de programación R, aquí es mucho más rápido hacer la descarga de información, sumado a que ya tendríamos la tabla cargada en R para hacer depuración de datos, análisis exploratorio espacial, entre otros.
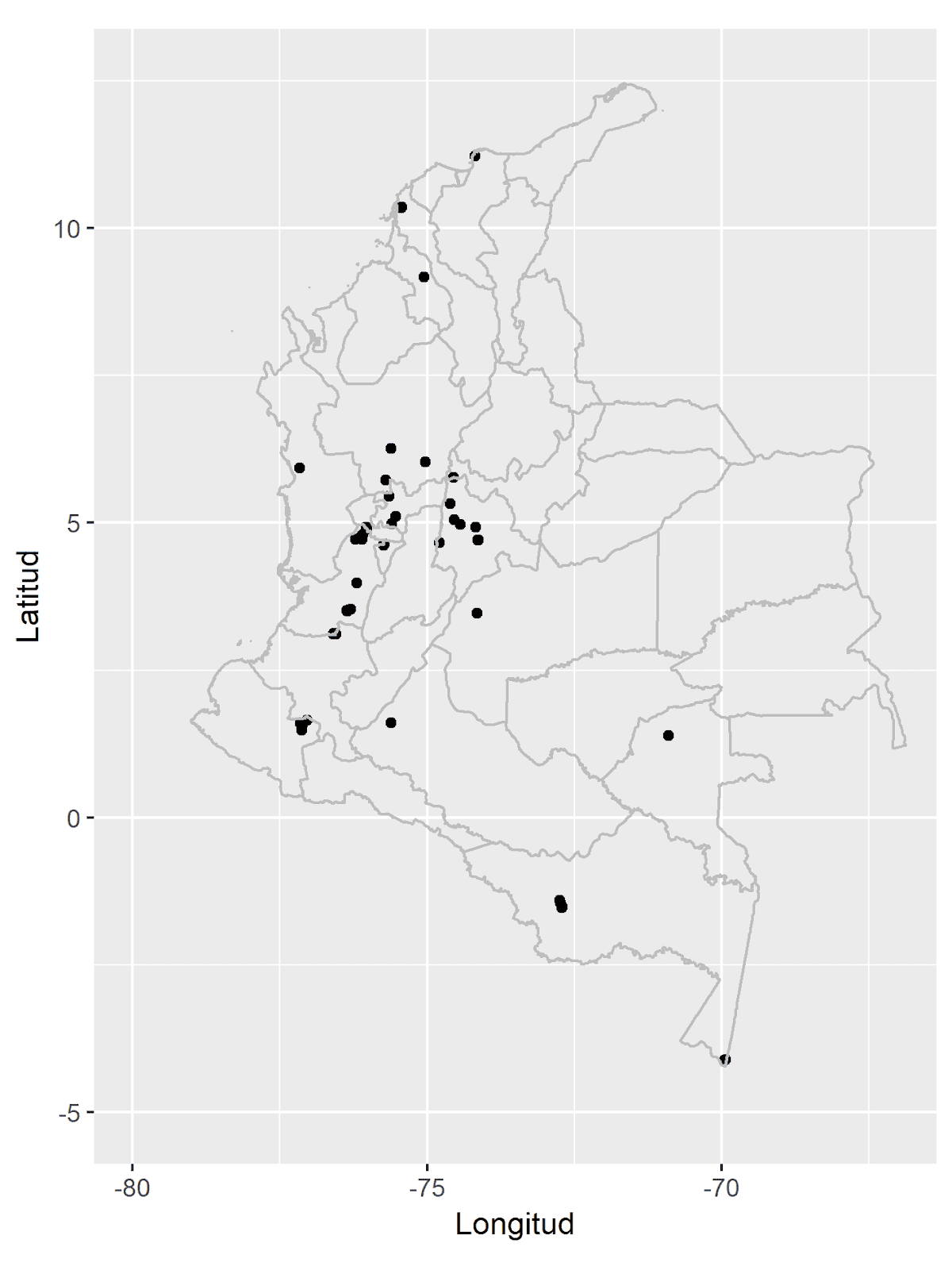
En este tutorial entonces se explicara como hacer la descarga de registros de la especie Musa paradisiaca haciendo uso de R, y luego como obtener unicamente los registros localizados en el país de Colombia.
Se sugiere tener un nivel básico en el manejo de R para realizar el ejercicio, sin embargo, se espera ser lo más claro posible para que pueda ser replicado sin mayor problema. Se require tener instalado el software R Studio.
Cómo primer paso se descarga la libreria de RGBIF, tambien se instalara la libreria Tidyverse (para hacer manejo de la tabla de una manera más facil).
install.packages('rgbif')
install.packages('tidyverse')
library(rgbif)
library(tidyverse)
Ahora se hará la respectiva descarga de los datos para la especie Musa Paradisiaca (conocida popularmente como banano).
occ <- occ_data(scientificName = 'Musa paradisiaca L.',
limit = 200000,
hasCoordinate = TRUE,
hasGeospatialIssue = FALSE)
Ahora conoceremos los nombres de las columnas. Las tablas descargadas de RGBIF siguen la estructura de darwin core (conocer más de este formato aquí).
colnames(occ$data)
Una de las columnas incluye el nombre del país (country), entonces, con base en esta columna haremos el respectivo filtro para obtener los registros localizados unicamente en Colombia.
occ_col <- filter(occ$data, country == 'Colombia')
Con esto entonces, el objeto occ_col contiene unicamente las presencias de la especie Musa Paradisiaca para el país de Colombia. Ahora hacemos la descarga del shapefile de los departamentos de Colombia, y se procede a la realización de un mapa sencillo, para visualizar en donde se encuentran los puntos de Musa paradisiaca en Colombia según esta base de datos de GBIF.
shp <- raster::getData('GADM', country = 'COL', level = 1)
gg <- ggplot() +
geom_point(data = occ_col, aes(x = decimalLongitude, y = decimalLatitude), color = 'black') +
geom_polygon(data = shp, aes(x = long, y = lat, group = group), color = 'grey', fill = NA) +
coord_fixed(ylim = c(-5, 12.5), xlim = c(-80, -67)) +
xlab('Longitud') +
ylab('Latitud')
ggsave(plot = gg, filename = 'myMap.png', units = 'cm', width = 12, height = 16, dpi = 300)
Ahora finalizamos haciendo la escritura de la tabla en nuestro espacio de trabajo:
write.csv(occ_col, 'occ_musa_paradisiaca.csv', row.names = F)
El mapa que generamos con el objeto gg debería ser similar al siguiente:
Hola a todos!
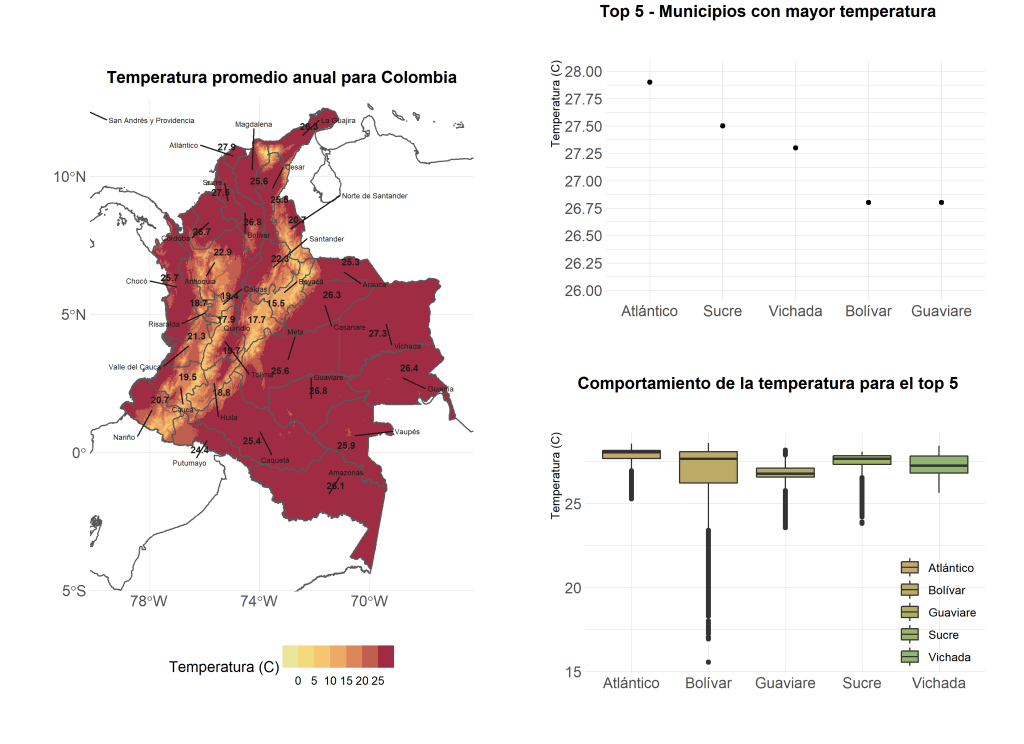
En este tutorial realizaremos un mapa de una variable continua en R, en el cuál utilizaremos archivos espaciales tipo raster, y shapefile. Este mapa representará la ubicación geográfica de estaciones meteorológicas de precipitación, así como tambien la temperatura promedio para el departamento del Valle del Cauca. En caso que quiera replicar el ejercicio puede descargar los datos aquí.
Aquí se hacen uso de algunos comandos como filter, select, extract, which, getData.
El primer paso a realizar es cargar las librerias, aquí usamos el comando p_load de la libreria pacman para cargar varias librerias en una sola línea, además, en caso que la libreria no encuentre instalada, ésta se instalará automaticamente.
require(pacman)
pacman::p_load(raster, rgdal, tidyverse, rgeos, gtools, stringr, foreign)
El segundo paso es cargar la tabla con las coordenadas geográficas de las estaciones de Worldclim.
wcs <- read.dbf('_dbf/wc_tean_stations.dbf')
Como tercer paso esta descargar el límite administrativo del Colombia a nivel administrativo 1 y 2.
col <- raster::getData('GADM', country = 'COL', level = 1)
col2 <- raster::getData('GADM', country = 'COL', level = 2)
tmn <- raster::getData('worldclim', var = 'tmean', res = 0.5, lon = coordinates(vll)[[1]], lat = coordinates(vll)[[2]])
El cuarto paso es realizar la extracción por máscara unicamente para el Valle del Cauca; pues los datos descargados corresponden a una ventana que contiene todo Colombia y algunos países centroamericanos.
vll <- col[col@data$NAME_1 %in% 'Valle del Cauca',]
vl2 <- co2[co2@data$NAME_1 %in% 'Valle del Cauca',]
tmn <- raster::crop(tmn, vll) %>% raster::mask(vll)
Ahora si realizamos un plot sencillo de los datos raster podemos observar que hay una grande zona en la que no hay datos, aquí se podría hacer una exclusión de estos datos NA del raster, siguiendo este proceso:
plot(tmn)
xNA <- is.na(tmn)
colNotNA <- which(colSums(xNA) != nrow(x))
rowNotNA <- which(rowSums(xNA) != ncol(x))
croppedExtent <- extent(tmn,
r1 = rowNotNA[1],
r2 = rowNotNA[length(rowNotNA)],
c1 = colNotNA[1],
c2 = colNotNA[length(colNotNA)])
tmncut <- raster::crop(tmn, croppedExtent)
Ahora bien, procedemos a realizar el calculo del promedio de la temperatura de los 12 meses del año y a su vez se divide el raster entre 10 (pues los datos en crudo vienen multiplicados por 10), esto mediante las siguientes dos líneas de comando.
tmn.avg <- mean(tmncut)
tmn.avg <- tmncut / 10
El siguiente paso es hacer el filtro de las estaciones climáticas únicamente para Colombia, a su vez solo escogemos las columnas country, name, long y lat.
wcs <- wcs %>%
as.tibble() %>%
dplyr::filter(COUNTRY == 'COLOMBIA') %>%
dplyr::select(COUNTRY, NAME, LONG, LAT)
Ahora el siguiente paso es realizar la extracción de los nombres de los departamentos para las estaciones, para eso hacemos uso del shape de nivel administrativo 2 así como tambien de la tabla de las estaciones meteorológicas
wcs <- raster::extract(co2, wcs[,c('LONG', 'LAT')]) %>% dplyr::select(NAME_1, NAME_2) %>% cbind(wcs, .)
wcs <- wcs %>% dplyr::filter(NAME_1 == 'Valle del Cauca')
Ahora sí, procedemos a realizar el mapa haciendo uso de funciones de la libreria ggplot.
gg <- rasterVis::gplot(tmn.avg) +
geom_tile(aes(fill = value)) +
scale_fill_gradientn(colours = RColorBrewer::brewer.pal(n = 8, name = "YlOrRd"), na.value = 'white') +
labs(fill = '') +
geom_polygon(data = vl2, aes(x=long, y = lat, group = group), color = 'grey', fill='NA') +
geom_polygon(data = col, aes(x=long, y = lat, group = group), color = 'grey', fill='NA') +
coord_equal(xlim = c(-77.6, extent(vl2)[2]), ylim = extent(vl2)[3:4]) +
xlab('Longitud') +
ylab('Latitud') +
theme_bw() +
theme(panel.background = element_rect(fill = 'white', colour = 'black'),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
legend.position = 'top')
gg <- gg +
geom_point(data = wcs, aes(x = LONG, y = LAT), col = 'blue')
Sí queremos visualizar el mapa escribimos
gg
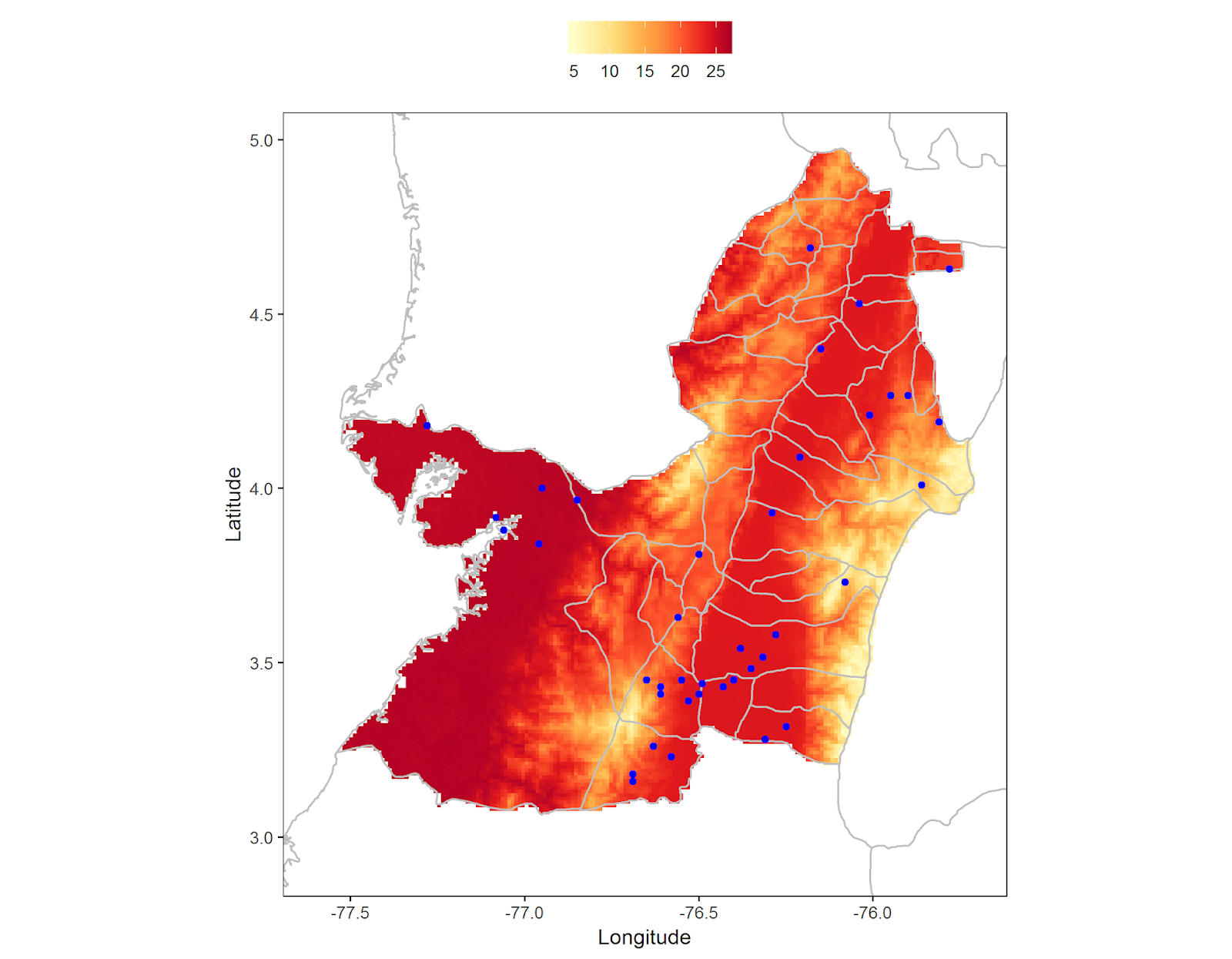
Por último, procedemos a hacer el guardado de nuestro mapa:
ggsave(plot = gg, filename = 'myMap.png', unit = 'in', width = 9, height = 7, dpi = 300)
En este tutorial trabajaremos con datos climáticos descargados de la pagina web de CRU (Climatic Researc Unit), se realizará la descarga, y tratamiento de los datos espaciales con el fin de realizar gráficas de tendencia a lo largo de 35 años (1980-2015); todo lo anterior lo realizaremos en el lenguaje de programación R. Las variables disponibles para descarga son las siguientes:
– cld: cobertura de nubes (%)
– dtr: rango temperatura diurno (grados centigrados)
– fdf: frost day frequency (días)
– pet: evapotranspiración potencial (mm/day)
– pre: precipitation (mm por mes)
– rhm: humedad relativa (porcentaje)
– ssh: sunshine duración (hours)
– tmp: temperatura promedio (grados centigrados)
– tmn: promedio de temperatura minima (grados centigrados)
– tmx: promedio de temperatura máxima (grados centigrados)
– presión de vapor (hectopascal hPa)
– wet: frecuencia de días húmedos (días)
– wnd: velocidad del viento (metros por segundo)
En este ejercicio usaremos las variables de precipitación, temperatura máxima, promedio y mínima. Para la realización de este ejercicio utilizaremos información que descargaremos durante el mismo tutorial. Se recomienda tener un nivel básico de programación para poder entender este tutorial, sin embargo, se intentará explicar las lineas a utilizar.
A continuación, listaremos los pasos a realizar explicando cada uno de ellos.
1. Cómo primer paso esta la instalación de los paquetes a utilizar en el sitio web.
# Load libraries
if(!require(raster)){install.packages('raster'); library(raster)} else {library(raster)}
if(!require(raster)){install.packages('rgdal'); library(raster)} else {library(rgdal)}
if(!require(tidyverse)){install.packages('tidyverse'); library(tidyverse)} else {library(tidyverse)}
if(!require(utils)){install.packages('utils'); library(utils)} else {library(utils)}
if(!require(gtools)){install.packages('gtools'); library(gtools)} else {library(gtools)}if(!require(velox)){install.packages('velox'); library(velox)} else {library(velox)}if(!require(stringr)){install.packages('stringr'); library(stringr)} else {library(stringr)}
2. Luego procedemos a configurar las variables y los años a descargar, para ello creamos los objetos vars, yr.start y yr.end; además establecemos la ruta base.
path_base <- 'https://crudata.uea.ac.uk/cru/data/hrg/cru_ts_4.01/cruts.1709081022.v4.01/'
vars <- c('pre', 'tmn', 'tmx', 'tmp')
yr.start <- c(1981, 1991, 2001, 2011)
yr.end <- c(1990, 2000, 2010, 2016)
3. Ahora procedemos a crear dos ciclos, haciendo uso del comando lapply, para descargar tanto las 4 variables como los distintos periodos de tiempo, de manera automática.
lapply(1:length(vars), function(v){
print(vars[v])
lapply(1:length(yr.start), function(x){
print(yr.start[x])
download.file(url = paste0(path_base, vars[v], '/cru_ts4.01.', yr.start[x], '.', yr.end[x], '.', vars[v], '.dat.nc.gz'),
destfile = paste0('_raster/_gz/', vars[v], '_', yr.start[x], '_', yr.end[x], '.nc.gz'),
mode = 'wb')
})
})
4. Como siguiente paso procedemos a descomprimir los archivo .gz obtenidos, para ello hacemos uso de las siguientes lineas. En el parametro destname establecemos la ruta donde queremos guardar nuestro conjunto de datos.
Todos los archivos resultantes los guardaremos en la carpeta nc (parámetro destname de la línea en la que usamos el comando gunzip).
gzfiles <- list.files('../_download/_raster/_gz', full.names = T, pattern = '.gz$')
nms <- basename(gzfiles) %>% gsub('.gz', '', .)
lapply(1:length(gzfiles), function(x){
print(gzfiles[x])
R.utils::gunzip(filename = gzfiles[x], destname = paste0('../_download/_raster/_nc/', nms[x]))
})
5. Ahora procedemos a listar los objetos que hemos descomprimido y luego las decadas de dichos archivos, estos elementos serán los parámetros a utilizar en la función que hará la extracción por máscara para Colombia de los archiovs, y luego la escritura de los mismos en una carpeta de nuestro espacio de trabajo.
ncfiles <- list.files('../_download/_raster/_nc', full.names = T, pattern = '.nc$')
decs <- basename(ncfiles) %>% str_sub(., start = 5, end = 13) %>% mixedsort() %>% unique()
col <- getData('GADM', country = 'COL', level = 0)
extNC <- function(vr, dec){
ncfile <- grep(vr, ncfiles, value = T) %>% grep(dec, ., value = T)
stk <- brick(ncfile)
stk.col <- raster::crop(stk, col) %>% raster::mask(., col)
nms <- names(stk.col) %>% gsub('\\.', '_', .) %>% str_sub(string = ., start = 2, end = 8)
lyrs <- unstack(stk.col)
Map('writeRaster', x = lyrs, filename = paste0('../_download/_raster/_tif/', vr, '_', nms, '.tif'))
print('Done!')
}
Aquí la aplicación de la función anteriormente creada. Este ciclo intera primero en la variable y luego en la decena, así primero extraera todos los períodos de tiempo y luego pasará a la siguiente variable, hasta completar las cuatro variables descargadas.
lapply(1:length(vars), function(v){
print(vars[v])
lapply(1:length(decs), function(d){
print(decs[d])
extNC(vr = vars[v], dec = decs[d])
})
})
6. En la función anterior logramos obtener, entonces, los archivos de precipitación, temperatura máxima, media y mínima para Colombia. Ahora plotearemos un archivo de ellos, y después convertiremos los archivos raster en tablas para de esta manera hacer gráficas de tendencia para las variables mencionadas anteriormente.
Lo primero que haremos en este paso será listar los archivos resultantes del pasos anterior, y luego a partir de un for crearemos 4 stacks, uno para cada variable, tal como se muestra a continuación:
fls <- list.files('../_download/_raster/_tif', full.names = T, pattern = '.tif$') %>% mixedsort()
for(i in 1:length(vars)){
eval(parse(text = paste0(vars[i], '<- grep(vars[', i, '], fls, value = T) %>% stack()')))
}
plot(pre[[1]])
7. Lo siguiente a realizar corresponde a la conversión de los archivos raster a tabla, para poder así crear las gráficas de tendencias. Aquí crearemos la función que realiza dicha conversión.
Lo primero que se realiza en la función es la conversión del stack a un objeto velox, esto pues es mucho más rapido las funciones de dicha libreria, luego extraemos las coordenadas de los raster, y luego con SpatialPoints convertimos las coordeanas en un shapefile, el siguiente paso es la extracción de los valores para todos y cada uno de los raster, luego y quizá estas son las lineas más complejas de entender, es la conversión de la matrix resultante en un data frame, aquí se realiza la asignación de un ID para cada píxel, así como también la creación de columnas que representan el año y el mes.
rstToTbl <- function(rst){
print(rst)
#rst <- pre
vlx <- velox(rst)
crd <- vlx$getCoordinates()
spn <- SpatialPoints(coords = crd)
vls <- vlx$extract_points(sp = spn)
rsl <- vls %>%
tbl_df() %>%
.[complete.cases(.),] %>%
mutate(ID = 1:nrow(.)) %>%
setNames(c(names(rst), 'ID')) %>%
gather(var, value, -ID) %>%
mutate(year = str_sub(var, 5, 8),
mnth = str_sub(var, 10, 11))
print('Done')
return(rsl)
}
Ahora aplicamos la función a las variables, para ello primero creamos una lista a partir de los objetos: pre, tmx, tmp, y tmn. Y seguido de ello con el ciclco del lapply aplicamos la función a la lista, el resultado será el objeto fnl (de final) que contendrá los cuatro tablas con la información climática de Colombia.
stks <- list(pre, tmx, tmp, tmn)
fnl <- lapply(1:length(stks), function(k) rstToTbl(rst = stks[[k]]))
8. Ahora haremos uso de funciones de la libreria ggplot para crear una gráfica para un píxel en particular. Sí Ud. lo desea puede crear un ciclo (lapply o for, por ejemplo) para crear una gráfica para cada píxel.
En este paso lo primero que haremos será un resumen anual de la precipitación, es decir, haremos la suma de la precipitación para los 12 meses de cada año, esto para un píxel en particular (ID = 300); luego crearemos el gráfico y estimaremos una gráfica de tendencia, vale aclarar que existen muchas maneras de realizarlo, este es solamente uno de ellas.
x <- fnl[[1]] %>%
filter(ID == 300)
x <- x %>%
group_by(year) %>%
summarize(sum = sum(value)) %>%
mutate(year = as.numeric(year))
gg <- ggplot(data = x, aes(x = year, y = sum)) +
geom_line() +
geom_smooth(method = 'lm') +
xlab('year') +
ylab('Prec (mm)') +
theme_bw()
ggsave(plot = gg, filename = 'prec_line.png', units = 'cm', width = 15, height = 13, dpi = 150)
El resultado debería ser algo como esto:

Sí has llegado hasta gracias por leer el tutorial, y por favor, no olvides compartirlo para que así este sea difundido de la mejor manera.